[本站讯]近日,软件学院陈勐副教授团队的多项研究成果在数据挖掘国际顶级会议KDD 2024 (CCF A)和人工智能国际顶级会议IJCAI 2024 (CCF A)正式发表。
MCLP:考虑用户偏好和时间规律性的位置预测算法
学术文章“Going Where, by Whom, and at What Time: Next Location Prediction Considering User Preference and Temporal Regularity”在CCF A类会议KDD 2024正式发表,博士研究生孙天骜为第一作者,陈勐副教授为通讯作者。
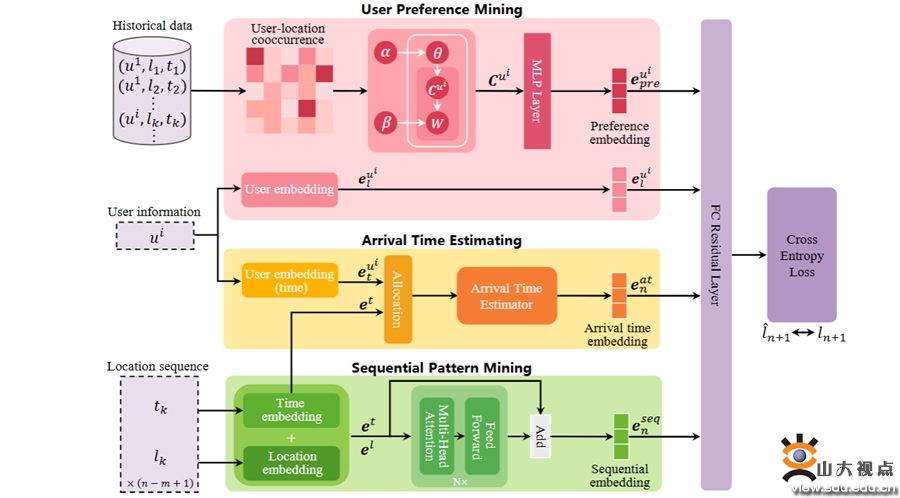
该研究指出,现有的人类移动预测模型在用户偏好和时间规律的利用上仍存在不足。尽管已有众多研究致力于下一个位置预测任务,但往往忽略了从人类轨迹中提取的用户偏好,同时也未能显式考虑到达时间这一关键因素。为了解决这些问题,本研究提出了一种多上下文感知的位置预测模型(MCLP),通过显式建模用户偏好和下一个活动位置的到达时间来预测个体的下一活动位置。首先,研究通过主题模型从历史轨迹中提取用户对不同活动位置的偏好。其次,设计了一个基于多头注意力机制的到达时间估计器,构建出稳健的到达时间嵌入。这两个组件为后续预测提供了重要的上下文信息。最后,利用Transformer架构挖掘序列模式,整合多种上下文信息进行下一个活动位置的预测。在两个真实世界的移动数据集上的实验结果表明,所提出的MCLP模型优于基线方法。
USPM:基于街景图像的半监督城市街道画像模型
学术文章“Profiling Urban Streets: A Semi-Supervised Prediction Model Based on Street View Imagery and Spatial Topology”在CCF A类会议KDD 2024正式发表,陈勐副教授为第一作者,硕士研究生李泽辰为第二作者,尹义龙教授为通讯作者。
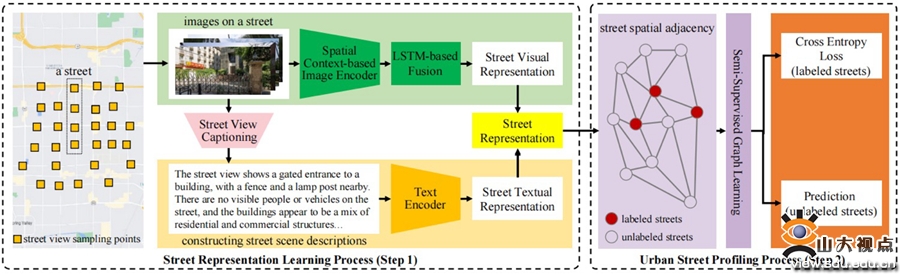
该研究探讨了如何利用街景图像有效地描述城市街道,即通过分析街道附近的多幅街景图像来预测其城市功能和社会经济指标。然而,研究面临两大挑战:一是街道上的众多街景图像呈现出复杂的空间分布关系,二是标注数据稀缺,只有少数街道有标注数据。为解决这些问题,研究提出了一种半监督的城市街道画像模型(USPM)。该模型结合街景图像、空间邻接性以及大语言模型来理解街景图像。具体而言,模型首先通过基于空间上下文的对比学习方法生成图像特征向量,并使用大语言模型生成街道场景的文本描述。随后,基于空间拓扑结构构建城市街道图,并采用半监督图学习算法进一步编码和预测。该研究利用真实数据集在两个下游任务上进行了实验验证,结果显示该模型均优于现有方法。
M3PA:基于街景图像和地点名称的兴趣点语义标注模型
学术文章“Exploring Urban Semantics: A Multimodal Model for POI Semantic Annotation with Street View Images and Place Names”在CCF A类会议IJCAI 2024正式发表,硕士研究生张大滨为第一作者,陈勐副教授为通讯作者。
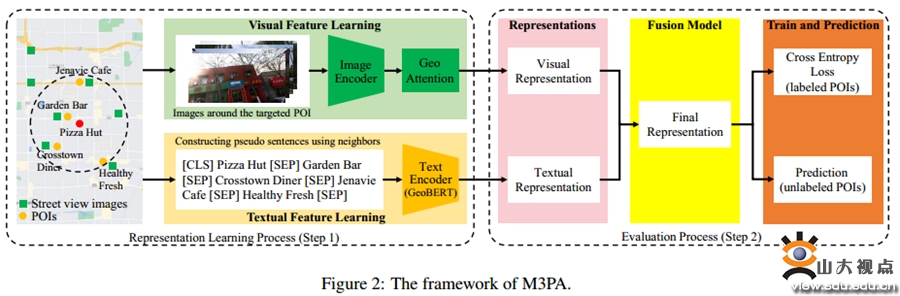
该研究指出,现有的兴趣点语义标注研究主要依赖于丰富的用户生成内容数据(如签到记录和用户评论)来提取与兴趣点相关的特征。然而,这些数据往往难以获得,尤其是对于新创建的兴趣点。为此,本研究旨在探索如何在信息有限的情况下(如仅依赖兴趣点名称和地理位置)进行兴趣点语义标注,并利用街景图像所提供的视觉信息捕捉兴趣点属性。研究提出了一种多模态兴趣点语义标注模型(M3PA),该模型将街景图像视为对有限兴趣点信息(如名称和地理位置)的重要补充。首先,它采用预训练策略引导图像编码器从街景图像中提取视觉特征,并整合附近兴趣点的视觉特征以生成视觉表征;其次,它结合空间相邻兴趣点的文本名称,通过地理语言模型生成兴趣点的文本表征。最后,将这两种表征融合在一起,实现兴趣点的语义标注。
SD-CEM:语义解纠缠的兴趣点类别表示学习模型
学术文章“Learning Hierarchy-Enhanced POI Category Representations Using Disentangled Mobility Sequences”在CCF A类会议IJCAI 2024正式发表,硕士研究生贾宏伟为第一作者,陈勐副教授为通讯作者。
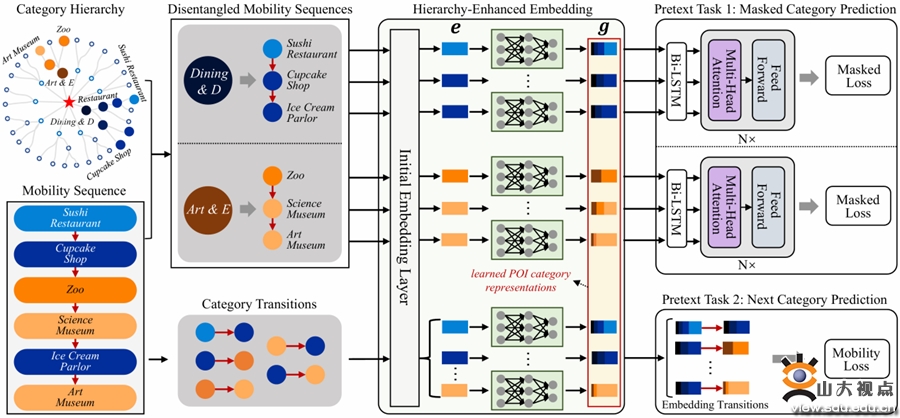
该研究指出,现有研究在捕捉兴趣点类别语义方面存在明显不足。目前的模型通常只对用户签到序列中的兴趣点上下文进行建模,并基于word2vec框架将类别嵌入潜在空间。然而,这种方法无法充分捕捉兴趣点类别之间的底层层次关系,也未能将类别层次结构有效融入各类深度序列模型中。为解决这些问题,本研究提出了一种语义解纠缠的兴趣点类别表示模型,利用解纠缠的移动序列生成层次增强的类别表示。该模型由三个模块组成:第一模块从原始人类移动数据生成语义解纠缠的移动序列;第二模块通过注意力机制利用兴趣点类别的层次结构学习层次增强的类别表示;第三模块结合两个训练任务来优化类别表示。该研究在两个真实签到数据集上进行了三项任务的实验验证,结果表明所提出的模型优于现有方法。
KDD(SIGKDD Conference on Knowledge Discovery and Data Mining)是数据挖掘领域的旗舰会议,也是中国计算机学会CCF推荐的A类会议。本届大会在Research Track共收到投稿2046篇,最终录用411篇,录用率为20%。IJCAI(International Joint Conference on Artificial Intelligence)是人工智能领域的旗舰会议,也是中国计算机学会CCF推荐的A类会议。本届大会共收到投稿5651篇,最终录用791篇,录用率为14%。

















