[本站讯]近日,山东大学公共卫生学院薛付忠教授团队青年教师侯庆振副研究员,依托国家健康医疗大数据研究院平台在蛋白质计算生物学领域取得系列研究进展,相关成果以第一作者或通讯作者发表于Journal of Chemical Theory and Computation(中科院一区,TOP期刊,IF 6.578),Briefings in Bioinformatics(数学与计算生物学一区,IF 13.994)和PLOS Computational Biology(中科院二区,TOP期刊,IF 4.779)等期刊。
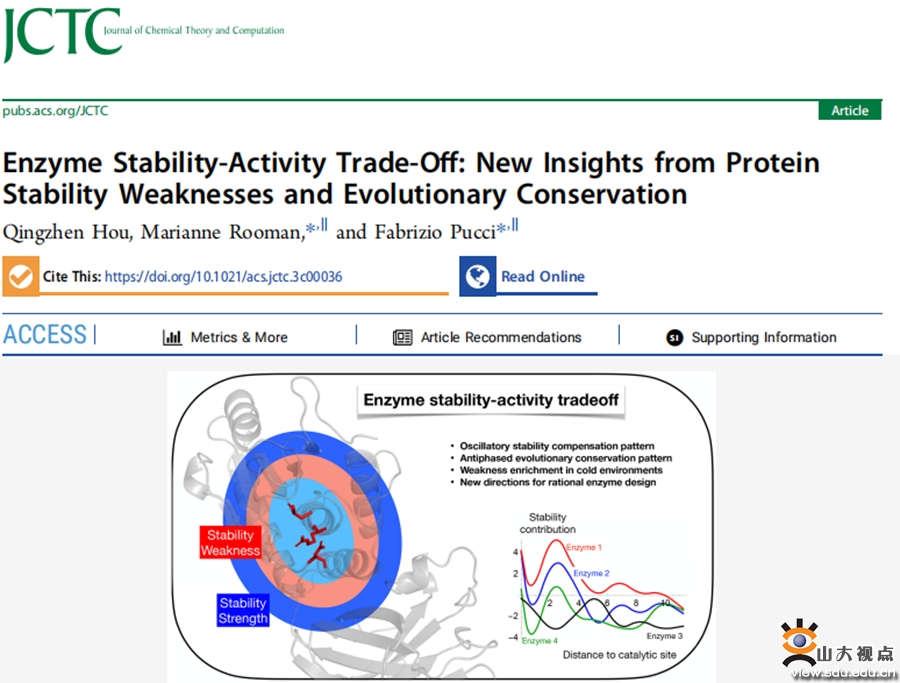
酶作为高效的生物催化剂,在生物技术和生物制药领域有着广泛应用。然而,酶活性和稳定性之间的精确平衡是发挥其功能的重要前提。但目前尚未明确酶的不同结构区域在不同环境下稳定性和活性的权重关系。本研究开发了一种基于统计势能的新算法,用于计算蛋白质三维结构区域的稳定性,以准确评估酶的稳定性。研究发现,酶的催化位点能量通常不稳定,在其周围存在独特的能量补偿机制,以实现活性和稳定性的平衡。这项研究对于酶的合理设计具有重要意义。相关论文在Journal of Chemical Theory and Computation杂志上发表,并被国际计算生物学学会(ISCB)选为ISMB/ECCB 2023会议的大会报告。山东大学为第一完成单位。

在疾病蛋白质组学和代谢组学研究中,酶促反应(enzymatic reaction)对于探索细胞过程中代谢物和蛋白质的机制功能以及了解疾病的病因至关重要。本研究开发了基于变分图自编码器的深度学习框架MPI-VGAE,通过加入蛋白质和代谢物的分子特征以及代谢网络中的临域信息,可准确预测不同物种中的蛋白-代谢酶促反应网络。在阿尔茨海默病和结肠直肠癌的蛋白与代谢组学研究中,该方法成功重塑了蛋白-代谢网络,发现了疾病关键的蛋白-代谢反应。论文发表在Briefings in Bioinformatics杂志,山东大学为第一完成单位和通讯作者单位。

大型语言模型(LLM)如ChatGPT等成为了热门的讨论话题。蛋白质序列与人类语言在某种程度上相似。蛋白质序列由20个氨基酸(字母)组成,形成功能区域(类似于单词),表达特定的功能(类似于语义)。基于蛋白质序列进行蛋白质结构功能的预测,并通过语言模型生成具有特定功能的蛋白,已成为生物医学研究中新的热点领域。本研究通过实例,总结了基于序列预测中需要注意的十大规则和应避免的错误,对于从事该领域研究的科研人员具有重要的启示作用。该论文已在PLOS Computational Biology杂志上发表,山东大学为第一完成单位。
以上研究得到了国家重点研发计划、国家自然科学基金项目、山东省自然科学基金项目、山东大学青年学者未来计划资助。
论文链接:
1、Enzyme Stability-Activity Trade-Off: New Insights from Protein Stability Weaknesses and Evolutionary Conservation
2.MPI-VGAE: protein–metabolite enzymatic reaction link learning by variational graph autoencoders
3、Ten quick tips for sequence-based prediction of protein properties using machine learning

















