[本站讯]近日,人工智能国际联合研究院(CFAIR)王峻教授团队在多聚类挖掘这一前沿研究课题上取得新进展,相关工作“Multiple Clusterings: Recent Advances and Perspectives”成功发表在计算机科学领域期刊Computer Science Review(中科院1区Top,IF=12.9)上,第一作者和通讯作者单位均为山东大学。

图1 传统聚类与多聚类的不同
传统聚类方法只能提供单一的聚类结果,将数据探索限制在单一规则和模式上。相比之下,多聚类可以同时或依次揭示多个非冗余的、不同的聚类模式,解决了传统聚类仅能找到单一语义聚类的难题(如图1所示),对全面理解大规模复杂数据中蕴含的规律具有重要意义。
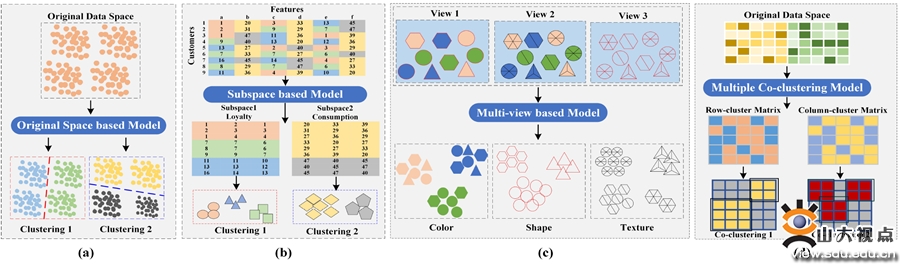
图2 四种类型的多聚类方法:(a)全空间,(b)子空间,(c)多视图数据,(d)多双聚类
在该工作中,团队对现有的多聚类方法进行了系统全面地探讨,根据四个不同的角度对现有方法进行了分类(如图2所示),总结了这些技术背后的关键思想,讨论了每种技术的优缺点,对多聚类的当前挑战和潜在应用方向进行了深度概述和讨论。在此基础上,团队构建了首个包含丰富多聚类资源的存储库MClustRep,收集了多聚类领域的基准数据集和核心代码,并搭建了首个开放的多聚类工具包MClustTool,为多聚类算法理论和应用研究作出了重要贡献。

图3 iMClusts在ALOI数据集中发现了两个聚类模式:形状聚类与颜色聚类

图4 scMCs成功在SNARE数据中发现了两个细胞聚类模式:细胞类型与细胞组织特异性
王峻教授团队长期聚焦现实场景中的数据分析难题,在面向大规模复杂数据的聚类分析领域进行了一系列创新研究工作,提出切实有效的针对性解决方法,在人工智能和数据挖掘领域的重要期刊IEEE TKDE’23/TCYB’21/TCBB’22、Machine Learning’21和计算机学报’19,及主流会议AAAI2019-20、IJCAI2019、ICDM2018-20、SDM2020等发表了多项代表性的研究工作。在多聚类算法的理论和应用方向的开创性研究成果受到多个领域的知名专家学者广泛引用和应用。在聚类分析理论方面,团队围绕多聚类算法的可解释性问题提出了可解释多聚类模型iMClusts,利用注意力机制与弱监督先验知识指导生成高质量、可解释的多样化聚类模式(如图3所示)。相关成果发表于数据挖掘领域主流期刊IEEE TKDE(中科院2区,IF=9.235,CCF A)。团队也成功将先进的多聚类理论应用到了单细胞数据挖掘领域,首次提出了用于单细胞数据多聚类挖掘的框架scMCs,联合建模单细胞转录组数据和表观遗传数据,探索多种不同的细胞聚类模式(如图4所示),开辟了单细胞数据挖掘的新方向。相关成果发表于生物信息学领域主流期刊Bioinformatics(中科院2区,IF=6.931,CCF B)。
团队目前正在围绕复杂疾病发生发展的时空多样性与异质性问题开展更深入的聚类分析研究工作,相关成果将直接促进对癌症等复杂疾病发生发展过程中不同层次生物实体间相互作用的深入理解。
上述研究工作由山东大学联合北京建筑大学、美国圣母大学和乔治梅森大学共同完成,得到了国家自然科学基金重点项目(62031003)、面上项目(62272268,62072380)、国家重点研发计划项目,泰山学者青年专家经费,华为-CAAI奖励基金等项目的资助。

















